在昨天,我們可以看到針對MNIST手寫辨識資料集,我們需要將其圖像轉換成一維的資料。但是這樣的做法在實際應用中顯得不太實際,因為大部分圖像都是彩色的,所以對於其資料維度應該是(batch_size, 寬, 高, 色彩通道)。假設我們的輸入是一張28x28的彩色圖像,這樣在給深度神經網路進行運算時,會產生28x28x3的輸入特徵。
這時就會導致輸入特徵越來越多,就會導致模型運算變得更加複雜,這樣子我們必須增加模型的參數量、深度,甚至增加資料集的數量,但資料蒐集的難度高標註的時間也要非常久,因此最合適的方法應該是我們需要使用其他模型來幫助我們達到目標,因此在今天我會告訴你卷積神經網路(Convolutional Neural Networks, CNN)在進行分類任務時常用的手段。
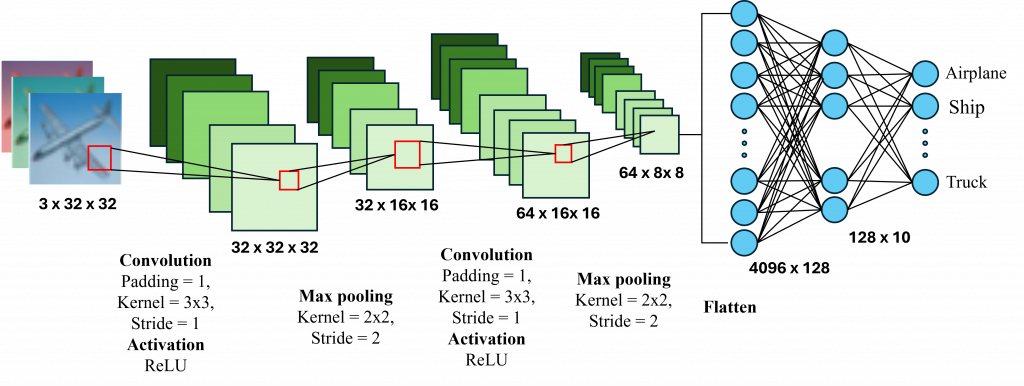
卷積神經網路是一種專門用來處理圖像資料的模型。它的概念是通過卷積核(Kernel)來提取不同層次的特徵。一個卷積神經網路通常包含卷積層、池化層以及全連接層。現在讓我們來看看在一個卷積神經網路中進行了哪些操作吧。
在卷積層(Convolution Layer)中其最重要的目的是通過卷積核來提取圖像中的局部特徵,以找出如邊緣、角點和更復雜的圖像結構,而其作法就是通過不斷的滑動卷積核並與其進行阿達瑪乘積(Hadamard product,符號⊗),我們可以看到下圖中的做法。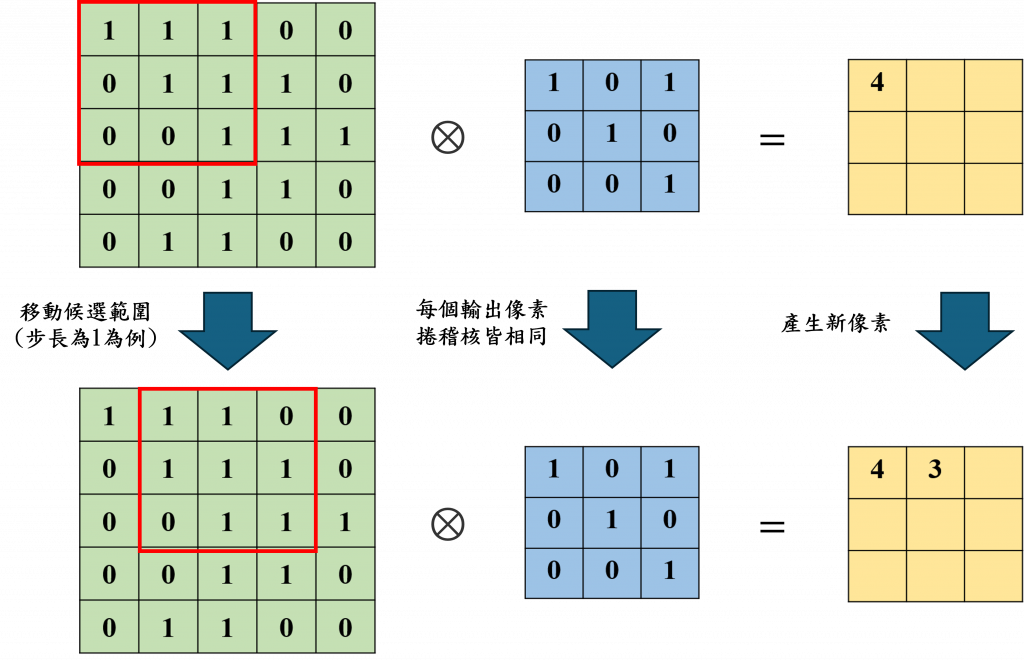
在上圖中我們可以看到原始圖像會與卷積核進行運算,並且通過設定步長 (Stride)來滑動卷積核的位置以產生新的圖像。不過我們會發現當卷積核滑動到底部和右邊邊緣時,卷積核的一部分會超出原始圖像的範圍。為了解決這個問題,我們需要使用填充 (Padding)技術。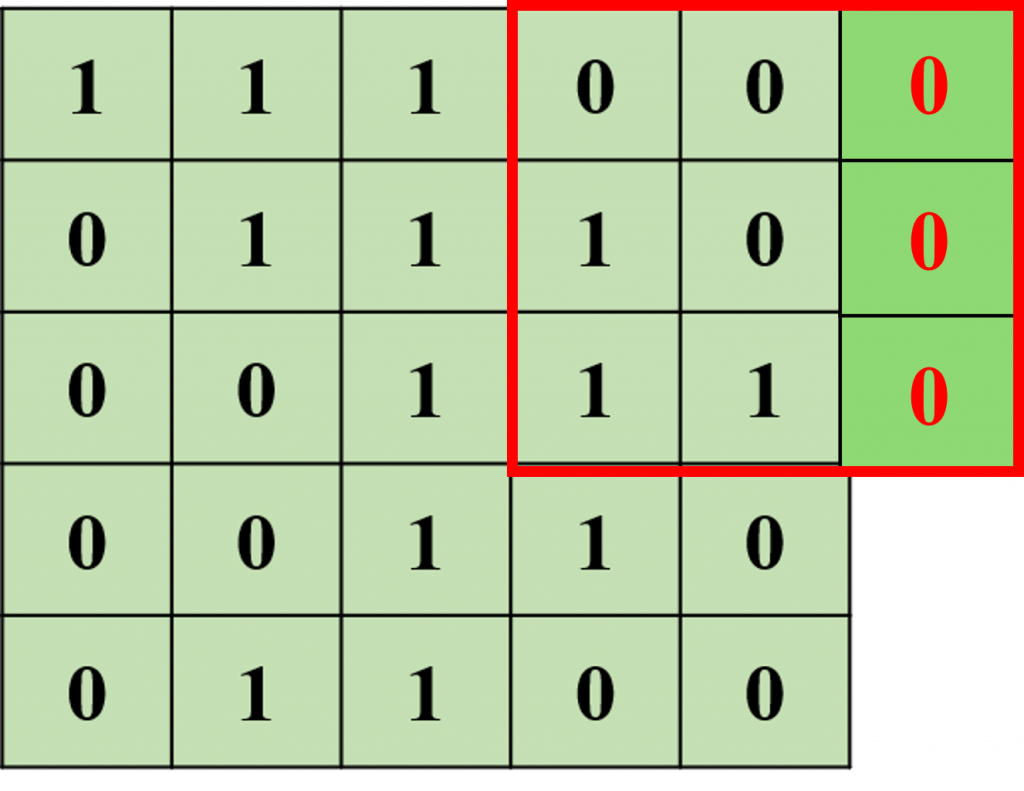
其中最常用的方法是零填充 (Zero Padding),即把超出邊界的部分補上0。這樣可以保持原始圖像的尺寸,從而產生最終的特徵圖 (Feature Map)。而對於卷積層我們可以用以下公式表達(I為輸入的圖像特徵、K為卷積核矩陣)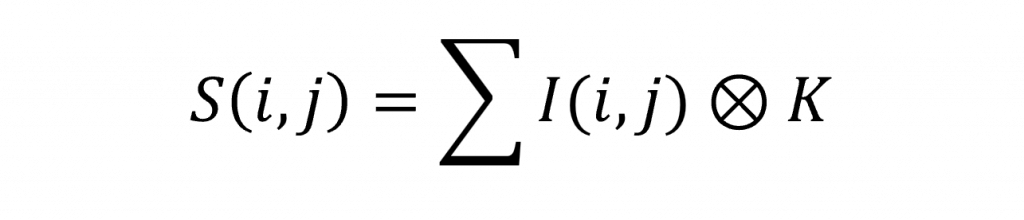
而通過應用不同的卷積核,每一層卷積層將會擷取到更加抽象和高階的特徵,而對於其特徵圖的長與寬我們則可以代入以下公式計算(k為卷積核大小、d卷積核之間的間隔數、s為步長、p為是否要進行填充)
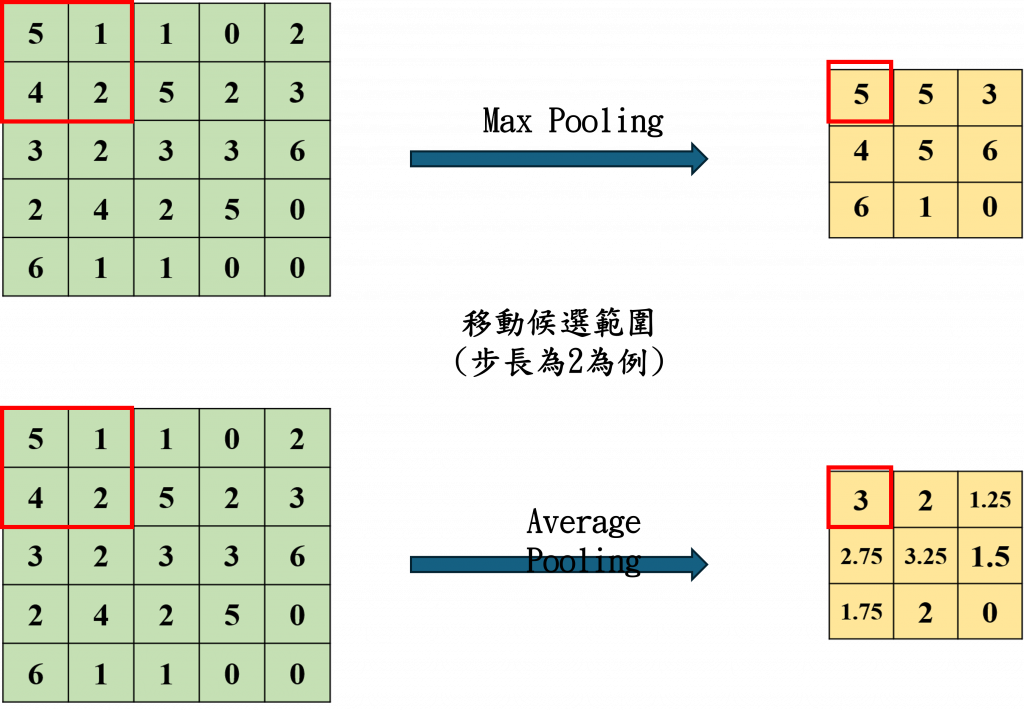
接下來是池化層(Pooling Layer),這一層的作用是為了減少圖像的空間維度,通常採用最大池化(Max Pooling)或平均池化(Average Pooling)來進行運算。
而在池化層中透過設定步長來選擇對應的目標範圍,並在這個範圍內計算平均值或找出最大值。有這一層的原因是我們通常會將一張圖像經過多次運算轉變為高維度的特徵圖,因此透過減少運算量可以防止過度擬合(Overfitting)的問題。在這裡我們可以來看到其數學公式如下(上公式為最大池化、下公式則為平均池化):
過度擬合是指模型在訓練集上表現良好,但在驗證或測試集上表現不佳的一種現象。這表示模型的複雜性過高,使其過分記住訓練集上的特徵,反而讓模型失去了泛化性。因此在設計適當的模型大小與深度時,必須參考資料集的大小,才能達到較佳的模型效果。
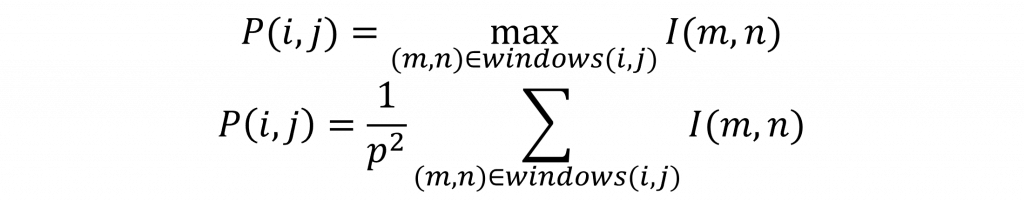
同樣的該層的特徵圖的長與寬我們同樣的可以使用卷積核的計算公式進行運算。
在我們討論了卷積神經網路的兩個層級之後,你可能會問為什麼需要計算每一層的輸出長度和寬度。這樣做的重要原因在於,卷積層和池化層主要負責提取圖像的特徵,而實際的計算工作大多數是在全連接層中進行。因此我們需要知道在設計時設定的特徵圖數量,以及經過一連串卷積層後的圖像尺寸。這樣我們才能將這些數據攤平(Flatten),讓全連接層進行運算。前面的章節中我們已多次講解過全連接層的計算公式,所以在這裡就不再詳細說明。
在昨天的內容中,我們使用了 交叉熵損失(CrossEntropyLoss) 函數,該函數主要應用於分類任務。其數學公式相對簡單,通過真實標籤的概率分佈 p(i) 與預測的概率分佈 p\hat(i) 進行運算,並對每一類進行 log 運算後相乘。我們通過這種方式懲罰預測概率與真實標籤(標籤值為 1)的差異,同時對其他類別的預測概率與 0 之間的差異進行處理。
如下圖所示的公式是用於多分類預測問題時的交叉熵計算。在這種情況下我們會使用 softmax 激勵函數將預測結果 y\hat 轉換為概率分佈,而不僅僅是直接的數值。至於 p(i),它的取值是 1(對應真實標籤)或 0(非真實標籤)。
在Pytorch中,我們不需要對最後一層進行
softmax運算,其原因是在Pytorch中的CrossEntropyLoss函數中內建了softmax運算。因此,我們切記不能再次加入softmax,不然會導致運算效果不如預期。
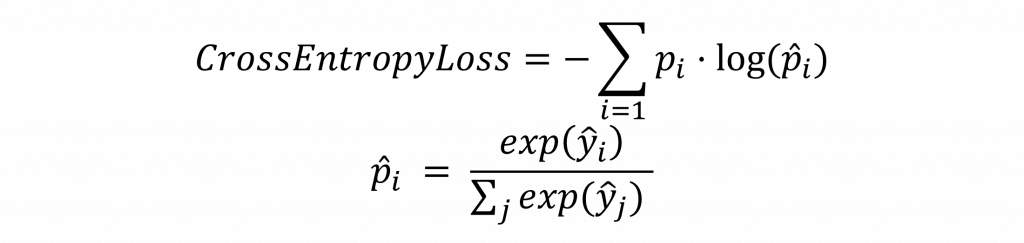
通常在卷積神經網路的應用中,多會使用這個損失函數來進行運算。我們在日常生活中其實經常遇到這類技術的應用,例如車牌辨識、人臉辨識、口罩辨識等系統,就是通過卷積神經網路與該損失函數所衍生出來的。
在今天我們特別解析了卷積神經網路的模型結構以及其數學公式,其中最重要的部分其實是計算每一層的特徵圖大小,因為當我們將特徵圖輸入全連接層時,需要在Pytorch中手動計算這些大小。因此當我們在撰寫一些通用的輸入公式時,這些計算公式就變得特別重要。
另外我們也解釋了昨天使用的損失函數的原理,讓你對分類任務中的損失函數有更深刻的理解。同時我們也能瞭解到,為什麼在昨天的內容中,儘管沒有使用到softmax這個激勵函數,我們仍然能夠計算每一個輸出的機率。

